Project Overview
The Spam Detection project aimed to build a highly accurate machine learning classifier to distinguish spam emails from legitimate messages. Using a dataset of 5,000 labeled emails, the project compared three different models: Bernoulli Naive Bayes, Support Vector Machine (SVM), and Random Forest. The emails were processed using TF-IDF vectorization, which converted text into numerical representations based on word frequency and importance. Each model was trained and evaluated using key classification metrics like precision, recall, and F1-score, ensuring the models could minimize false positives while still detecting spam emails.
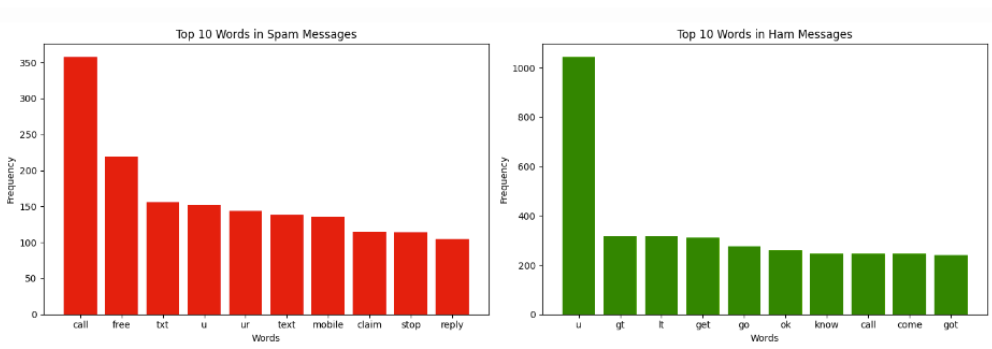
On the right, we can see the word count of different words in spam vs ham (not spam) messages. This shows the differences in the construction of each kind of message, and how we are able to exploit those differences by training a machine learning model.
One of the biggest challenges was hyperparameter tuning to maximize model performance. The Bernoulli Naive Bayes classifier initially had a recall score of 79.9%, but through optimization, it improved to 93.5%, significantly reducing missed spam emails. The SVM model achieved the highest precision (97.3%), while the Random Forest model reached 100% precision but struggled slightly with recall. The final ensemble model combined insights from all three approaches, leading to 98% overall accuracy. Future improvements involve leveraging deep learning techniques such as Recurrent Neural Networks (RNNs) or Transformers (BERT) to further enhance spam classification accuracy in real-world applications.